Столбцы в pandas
Contents
Столбцы в pandas#
Резюмируя содержание предыдущей страницы, столбцы таблиц в pandas представляются объектами pandas.Series, у которых есть сходства и различия с одномерными массивами NumPy: оба являются последовательностями данных (т.е. элементы столбца пронумерованы и по номеру можно получить доступ к соответствующему значению в столбце) одного типа, но в отличие от массивов NumPy столбцы pandas поддерживают продвинутую индексацию.
Кроме этого важно помнить, что содержимое столбцов pandas изменяемо, а длина — нет.
horizontal_line = "_" * 80
Создание#
Создать столбец pandas можно многими разными способами. Сам по себе pandas столбец обычно создают конструктором pandas.Series. С помощью него создать столбец можно из
скаляра (число,
str);последовательности (
list,np.arrayи т.д.);словаря.
Можно создать и пустой pd.Series, но большого смысла в этом нет из-за невозможности наращивать длину столбца на месте.
Скаляр#
Если передать в качестве параметра скаляр, то создаётся столбец из одного элемента. При этом строка тоже считается скаляром, несмотря на то, что она формально является последовательностью.
import pandas as pd
import numpy as np
s = pd.Series("abc")
s
0 abc
dtype: object
Вывод сообщает, что s — столбец из одного элемента "abc" типа object, индекс которого равен 0.
object— самый общий тип данных в столбце. Вpd.Seriesтипаobjectможно хранить данные любого типа, но этого следует по возможности избегать из соображений производительности, читабельности и удобства применений методов библиотекиpandas. Указать тип столбца можно дополнительным параметромdtype(“string” для строк).при создании
pd.Seriesскаляра, индекс единственного элемента будет равен 0. Можно явно указать индекс с помощью параметраindex.
s = pd.Series("abc", dtype="string", index=[42])
s
42 abc
dtype: string
Последовательность.#
Более содержательный пример — создание pd.Series из списка или массива NumPy.
data = [7, 12, 42]
s = pd.Series(data)
s
0 7
1 12
2 42
dtype: int64
По умолчанию генерируется RangeIndex, который соответствует смещению. При необходимости можно в явном виде указать необходимый индекс в виде последовательности той же длинны: за это отвечает параметр index.
index = ["a", "b", "c"]
s = pd.Series(data, index=index)
s
a 7
b 12
c 42
dtype: int64
На самом деле данные столбца хранятся в массиве NumPy, к которому можно получить доступ по атрибуту values столбца.
values = s.values
print(f"{values=}")
print(f"{type(values)=}")
values=array([ 7, 12, 42], dtype=int64)
type(values)=<class 'numpy.ndarray'>
Код в ячейке ниже демонстрирует, что изменение в возвращенном массиве отражаются на исходном столбце.
print(s)
print(horizontal_line)
values[0] = 0
print(s)
a 7
b 12
c 42
dtype: int64
________________________________________________________________________________
a 0
b 12
c 42
dtype: int64
Тип столбца выводится согласно правилам NumPy: наиболее общий тип (вплоть до object), если не указывается явно.
Словарь#
При создании pd.Series из словаря, ключи попадают в индекс столбца, а значения попадают в данные столбца.
d = {"a": 7, "b": 12, "c": 42}
s = pd.Series(d)
s
a 7
b 12
c 42
dtype: int64
Индексация#
Подробнее разберем особенности индексации объектов pandas. Индексация строк таблиц очень похожа на индексацию элементов столбца, и многие утверждения в этом разделе работают аналогично и в случае таблиц pandas.
Индексация по метке vs индексация по смещению#
Индексация с помощью .loc[] vs .iloc[]#
Получать значение из столбца можно двумя способами:
Продемонстрируем разницу между “.loc[]” и “.iloc[]” на примере столбца из предыдущего раздела.
print(s)
a 7
b 12
c 42
dtype: int64
Индексирование с помощью “.iloc[]” эквивалентно индексированию лежащему под капотом массиву NumPy, т.е. это индексирование по смещению.
for i in range(3):
print(f"{i=}: {s.iloc[i]=}")
i=0: s.iloc[i]=7
i=1: s.iloc[i]=12
i=2: s.iloc[i]=42
Индексирование с помощью “.loc[]” подразумевает использование индекса столбца, т.е. доступ осуществляется по метке.
for label in "abc":
print(f"{label=}: {s.loc[label]=}")
label='a': s.loc[label]=7
label='b': s.loc[label]=12
label='c': s.loc[label]=42
Индексация с помощью [] и почему рекомендуется её избегать#
Вообще говоря, можно использовать для индексации и просто “[]”. Тогда способ индексации определятся по переданному значению. В нашем примере метки представляются строками, а значит если указать между пары квадратных скобок строку, то индексация будет произведена по метке.
for i in range(3):
print(f"{i=}: {s[i]=}")
print(horizontal_line)
for label in "abc":
print(f"{label=}: {s[label]=}")
i=0: s[i]=7
i=1: s[i]=12
i=2: s[i]=42
________________________________________________________________________________
label='a': s[label]=7
label='b': s[label]=12
label='c': s[label]=42
Если индекс столбца сам по себе является целочисленным (например, создаваемый по умолчанию RangeIndex), то при использовании “[]” pandas попытается индексировать именно по метке.
s = pd.Series(data=[7, 13, 42], index=[7, 13, 42])
print(s)
print(horizontal_line)
for label in (7, 13, 42):
print(f"{label=}: {s[label]=}")
print(horizontal_line)
try:
s[0]
except KeyError:
print("Ошибка при обращении по метке '0'.") # Только в случае ошибки
7 7
13 13
42 42
dtype: int64
________________________________________________________________________________
label=7: s[label]=7
label=13: s[label]=13
label=42: s[label]=42
________________________________________________________________________________
Ошибка при обращении по метке '0'.
Нередко осмысленного индекса придумать не удаётся и вы довольствуетесь сгенерированным по умолчанию RangeIndex. В таком случае следует проявлять особую осторожность. Хотя изначальный индекс и совпадает с индексацией по смещению, а значит “[]”, “.loc[]” и “.iloc[]” произведут одинаковый эффект. Однако в процессе работы могут получиться столбцы, у которых такое свойство нарушится, что может привести к логическим ошибкам.
Для демонстрации создадим новый столбец s.
s = pd.Series([1, 2, 3])
print(s)
print(horizontal_line)
for i in range(3):
print(f"{i=}: {s[i]=}, {s.iloc[i]=}, {s.loc[i]=}")
0 1
1 2
2 3
dtype: int64
________________________________________________________________________________
i=0: s[i]=1, s.iloc[i]=1, s.loc[i]=1
i=1: s[i]=2, s.iloc[i]=2, s.loc[i]=2
i=2: s[i]=3, s.iloc[i]=3, s.loc[i]=3
Видим, что индексация с помощью “[]”, “.loc[]” и “.iloc[]” приводит к одинаковому результату.
Теперь извлечем последние два элемента этого столбца простым срезом.
tail = s.iloc[-2:]
print(tail)
1 2
2 3
dtype: int64
Обратите внимание, что в итоговом столбце метки начинаются с 1, а значит теперь индексация “.loc[]” и “.iloc[]” приведет к разным результатам.
for i in (0, 1):
print(f"{i=}: {tail.iloc[i]=}")
print(horizontal_line)
for i in (1, 2):
print(f"{i=}: {tail.loc[i]=}")
i=0: tail.iloc[i]=2
i=1: tail.iloc[i]=3
________________________________________________________________________________
i=1: tail.loc[i]=2
i=2: tail.loc[i]=3
Индексация с помощью “[]” в таком случае эквивалента индексации с помощью “.”, т.е. обращение по нулевому индексу s[0] — ошибка.
Warning
В связи с тем, что индексация с помощью “[]” явным образом не указывает, будет ли использоваться индексация по меткам или по смещению, а также из-за того, что использование “[]” предрасполагает к логическим ошибкам, разработчики и сообщество программистов рекомендуют не использовать “[]” для индексации столбцов pandas никогда и всегда использовать или “.loc[]” или “.iloc[]”, чтобы явно сообщить свои намерения.
Индексация по метке#
Индексация по смещению работает как в NumPy, а индексация по метке больше похожа на получения значений по ключу в словарях (dict). Однако пара отличий все же есть.
Во-первых, в метках могут содержаться дубликаты. Если индексировать по метке, которая встречается в индексе не единожды, то в качестве результата вы получите новый столбец.
duplicates = pd.Series([1, 2, 3], index=["a", "b", "b"])
print(duplicates)
print(horizontal_line)
duplicates.loc["b"]
a 1
b 2
b 3
dtype: int64
________________________________________________________________________________
b 2
b 3
dtype: int64
Во-вторых, можно за один раз извлекать сразу несколько элементов. Чтобы продемонстрировать, создадим новый столбец.
values = range(6)
index = list("aecdbf")
s = pd.Series(values, index)
print(s)
a 0
e 1
c 2
d 3
b 4
f 5
dtype: int64
Можно передать в “.loc[]” список меток и получить столбец с теми же значениями.
s.loc[["b", "c", "f"]]
b 4
c 2
f 5
dtype: int64
Если метки не содержат дубликатов, то можно применять срезы.
s.loc["e":"b"]
e 1
c 2
d 3
b 4
dtype: int64
Индексация булевыми масками#
Как и массивы NumPy столбцы pandas можно индексировать булевыми масками. в случае булевой маски mask, выражения “.loc[mask]” и “.iloc[mask]” делают одно и тоже, поэтому тут оправданно применение простых квадратных скобок “[]”.
mask = [False, False, True, False, True, True]
s[mask]
c 2
b 4
f 5
dtype: int64
По аналогии это позволяет применять логические операции к столбцам pandas и сразу же элегантно фильтровать значений.
s[(s >= 5) | (s <= 2)]
a 42
e 1
c 2
f 5
dtype: int64
Изменяемость pandas.Series#
Аналогично с массивами NumPy, можно изменять содержимое ячейки/среза, но нельзя изменять размер (длину) столбца.
Например, изменить содержимое ячейки по метке "a" можно изменить следующим образом.
print(s)
print(horizontal_line)
s.loc['a'] = 42
print(s)
a 0
e 1
c 2
d 3
b 4
f 5
dtype: int64
________________________________________________________________________________
a 42
e 1
c 2
d 3
b 4
f 5
dtype: int64
С изменением размера следует быть аккуратным. Следующая операция как бы увеличит размер столбца s.
print(s)
print(horizontal_line)
s.loc['z'] = 42
print(s)
a 0
e 1
c 2
d 3
b 4
f 5
z 42
dtype: int64
________________________________________________________________________________
a 0
e 1
c 2
d 3
b 4
f 5
z 42
dtype: int64
Но pandas перевыделяет память, копирует данные старого столбца и дозаписывает новое значение при каждом добавлении нового значения в столбец или новой строки в таблицу. Т.е. использовать объекты pandas для накопления строк по одной крайне неэффективно. Если есть такая необходимость, то обычно данные накапливают в контейнерах python (список, словарь) и трансформируют в pandas объект в самом конце или по накоплении некого блока информации. Альтернативой служит создание большой таблицы/столбца и работа только с первыми n строками, увеличивая n при необходимости.
Операции над столбцами#
При выполнении операций над столбцами метки играют важную роль. Например, при сложении двух столбцов складываются значения с одинаковыми метками. Индекс результирующего столбца — объединение индексов столбцов слагаемых, а напротив тех меток, которые присутствуют в индексе только одного столбца записывается значение np.nan.
s1 = pd.Series([1, 2, 3], index=["a", "b", "c"], dtype="int64")
print(s1)
print(horizontal_line)
s2 = pd.Series([10, 20, 30], index=["c", "b", "d"], dtype="int64")
print(s2)
print(horizontal_line)
s = s1 + s2
print(s)
a 1
b 2
c 3
dtype: int64
________________________________________________________________________________
c 10
b 20
d 30
dtype: int64
________________________________________________________________________________
a NaN
b 22.0
c 13.0
d NaN
dtype: float64
Рисунок ниже иллюстрирует, что произошло.
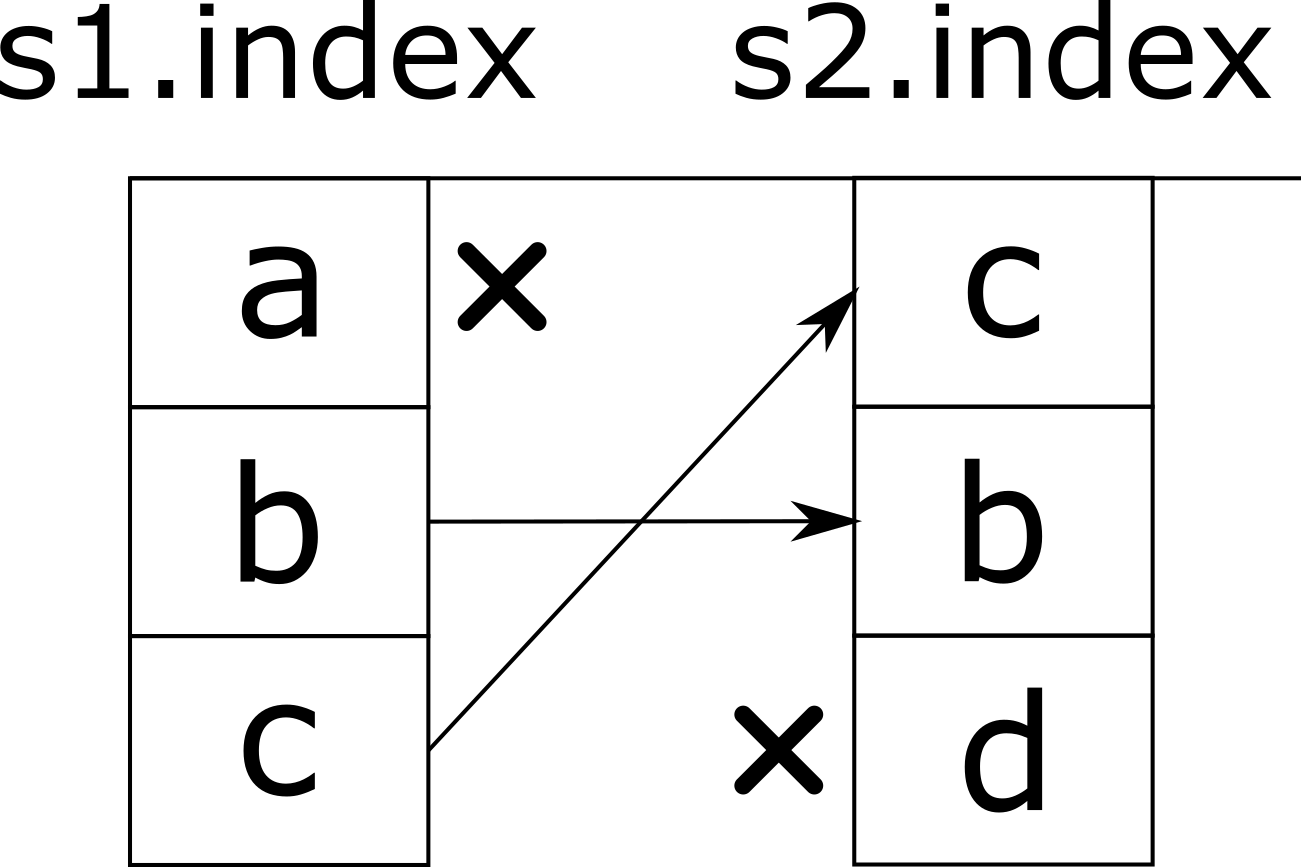
Также можно заметить, что данные результирующего столбца имеют тип float64, несмотря на то, что исходные столбцы целочисленного типа. Это объясняется тем, что появившееся значения NaN не могут быть представлены стандартным числовым типом, что вынуждает приведение к float. Избежать такого поведения можно используя расширенные целочисленные типы, для использования которых указывается тип с заглавной буквы “I”.
s1 = pd.Series([1, 2, 3], index=["a", "b", "c"], dtype="Int64")
print(s1)
print(horizontal_line)
s2 = pd.Series([10, 20, 30], index=["c", "b", "d"], dtype="Int64")
print(s2)
print(horizontal_line)
print(s1 + s2)
a 1
b 2
c 3
dtype: Int64
________________________________________________________________________________
c 10
b 20
d 30
dtype: Int64
________________________________________________________________________________
a <NA>
b 22
c 13
d <NA>
dtype: Int64
Большинство методов массивов NumPy переопределены в pandas для pd.Series таким образом, чтобы обрабатывать пропущенные значения.
pandas_mean = s.mean()
numpy_mean = np.mean(s.values)
print(f"{pandas_mean=}, {numpy_mean=}")
pandas_mean=17.5, numpy_mean=nan